안녕하세요 삽잡이 입니다.
오늘은 연결 리스트에 대해서 알아보도록 하겠습니다.
연결 리스트는 STL 에서 제공하는 자료구조 중에 하나로써,
비슷한 친구로 지난 시간에 배운 vector가 있습니다.
연결리스트는 '노드'들의 선형 집합을 말합니다.
영어로는 node. 즉, 나무 줄기의 마디를 뜻합니다.
이 글을 진행하다 보면 결국은 왜 node라고 표현하는지 감을 잡으실 수 있을 것입니다.
노드들의 선형 집합... 그렇다면 자료구조에서 노드는 뭐라고 정의를 하고 있는가?
바로, 데이터와 링크의 조합이라고 정의하고 있습니다.
그렇다면 데이터는 알겠고.... 링크는?
노드의 위치 정보라고 정의할 수 있습니다.
자 간략하게 연결 리스트에 사용되는 요소 및 용어에 대해서 알아봤습니다.
그렇다면, 이제 연결 리스트를 도식화 해보겠습니다.

노드가 하는 가장 중요한 역할을 데이터를 담고 있다는 것입니다. 당연한가요?
결국 자료구조는, 데이터를 효율적으로 보관할 수 있는 구조를 모아 둔 것이죠.
그러니, 자료를 보관하는 것이 핵심이기에, 자연스럽게 노드의 역할은 데이터를 보관하는 것입니다.
배열 음... 지난 시간에 배운 벡터와 비교해보도록 하지요...
이 둘의 공통점은 바로 선형이라는 것입니다.
하지만, 벡터의 경우 데이터가 보관하는 장소가 연속적이지만,
리스트의 경우에 데이터가 보관하는 장소가 독립적으로 되어있는 차이점을 가지고 있습니다.
따라서, 연결 리스트를 사용할 때에는 인덱스 연산자를 사용할 수 없게 됩니다.
연속적인 메모리 공간을 가지고 있지 않기 때문이라는 것입니다.
또한 벡터와 같이 저장소의 크기를 갱신할 필요가 없고, 용량을 얻어올 필요가 없게 됬습니다.
왜냐, 데이터 보관을 요청하면 바로 데이터를 저장할 노드를 생성하기 때문입니다.
이에 실제 STL 에서 제공하는 list에는
인덱스 연산자 중복 정의가 되어있지 않고 reserve, capacity 메서드 또한 제공하지 않습니다.
사실, vector나 list는 사용법이 비슷합니다.
실제 STL 에서 제공하는 라이브러리를 사용할 때
순차적으로 보관할 때에는 push_back, 삭제할 때는 iterator를 통해 검색하여 erase하고...
장 /단점을 살펴볼까요?
list를 사용할 때에는 자료를 추가할 때 언제나 같은 속도로 보관할 수 있습니다.
왜냐? 노드를 생성하고 추가하기만 하면 되거든요...
하지만, vector의 경우 중간에 데이터를 추가하고자 한다면
추가할 위치의 이후 값들을 모두 한칸 씩 뒤로 밀어야되기 때문에
자료의 개수에 따라 추가비용이 발생하게 됩니다. 삭제 또한 vector는 다르게 없죠...
전반적으로 삽입과 삭제에 들어가는 비용은 연결 리스트가 적게 듭니다.
그렇지만, 검색에 들어가는 비용은 비슷할 수 있겠지만,
vector는 인덱스 보관으로 해당 index에 바로 접근할 수 있기 때문에
이러한 점은 vector가 더 이점을 가지고 있죠...
그렇다면, 연결 리스트에 종류에 대해서 알아보도록 하겠습니다.
- 단순(simply), 단일(singly)

- 이중(doubly)
링크가 자기 뒤에 있는 노드 위치 정보만을 기억한다면 단순 연결 리스트라고 정의할 수 있으며,
자신의 앞쪽 위치 정보도 기억한다면 이중 연결 리스트로 정의할 수 있습니다.
추가적으로, 특수한 형태의 원형 연결 리스트도 있습니다.
원형 연결 리스트란, 맨 뒤에 있는 노드의 링크가 맨 앞에 노드를 가리키는 연결 리스트라고 할 수 있습니다.

자... 오늘은 Dummy Node가 있는 이중 연결 리스트를 소개하겠습니다.
여기서 head와 tail은 포인터입니다. 노드가 할당한 메모리 값을 가지고 있죠...
head는 맨 앞의 노드 위치 정보이며
tail은 맨 뒤의 노드 위치 정보라고 정의할 수 있습니다.
간단하게 순차보관을 하려면 어떻게 해야할까요?
간단하게, tail 위치의 앞에만 계속 보관하면 순차보관을 할 수 있겠군요...
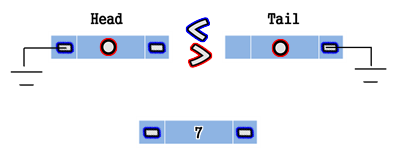
여기에서 노드를 하나 추가한다고 해보겠습니다.
추가적으로 순차적으로 보관한다는 옵션을 주겠습니다.
7이라는 데이터를 노드에 추가시키려고 합니다.
그러면 Head와 Tail이 가리키는 링크를 변경할 필요가 있겠습니다.

이와 같이 말입니다... 추가적으로 또 데이터를 추가해보록 하지요...
5의 값을 가지고 있는 노드를 추가한다고 해보겠습니다.
5는 7보다 작기 때문에 굳이 tail의 값은 변할 필요가 없을 것 같군요
보관하고자 하는 데이터를 노드로 생성했습니다.
head와 tail이라는 더미 노드가 있는 덕에, node(5)가 head를 가리키도록 하고
node(7)이 node(5)를 가리키게 하면 되겠군요.
그림은 생략하도록 하겠습니다... 하하... 어떻게 추가가 될지 상상이 되시죠?
절대 귀찮아서 그런게 아닙니다...
이렇게 추가를 하기 위해서는 우선 now (추가하고자 하는 노드)를 변경 시키도록 해보죠...
node (5) 가 head를 가리키도록 한 다음, node(7) 이 node(5)를 가리키게 합니다.
그 다음으로, head가 node(5)를 가리키도록 하고, tail이 node(7)을 가리키도록 하면 됩니다...
복잡하죠? 각각의 노드들은 독립성을 가지고 있기 때문에
이와 같이 4가지의 순서를 거쳐서 노드를 추가진행 할 수 있습니다.
물론 이 과정을 반드시 위와 같이 할 필요는 없습니다.
모두 24가지의 경우의 수가 있겠군요... 하지만 이 24가지의 모든 경우의 수가
노드를 추가하는데 사용될 수 있는 것은 아닙니다.
헷갈리신다면... 아니, 반드시 그림을 그려보시길 바랍니다.
그림을 그리며 이해할 수 있어야 됩니다. 자료구조는 철저하게 그림을 그려야 된다고 합니다.
그림을 그려서 코드를 만들 수 있어도, 코드를 작성하고 그림을 그리는 것이 아닙니다...
노드를 추가하는 것은 정말로 중요합니다. 이 구조를 이해할 수 있어야 됩니다.
추가를 했으니, 이제는 노드를 제거할 줄도 알아야 하지요...
제거를 하려고 한다면 어떻게 해야할까요?
연결을 끊을 때는 2가지의 경우의 수가 있습니다.
왜냐? 지울 노드는 그냥 소멸시키면 되기 때문에 굳이 지워질 노드의
prev / next 의 위치까지 고려할 필요가 없기 때문입니다.
자... 그렇다면 모든 연결리스트를 지울때에는 어떻게 해야할까요...
죽을 때에는 head와 tail도 모두 소멸 시켜야합니다.
모두 지울 때에는 두 가지의 방법이 있겠습니다.
1. 끝 값(tail)이 될 때까지 반복문을 돌리며
소멸 시킨 뒤 tail 이면 반복문을 종료 시키고 head /tail 소멸시키기.
2. 끝 값(tail)인지 확인하고 아니면 앞에 노드를 소멸 시킨 뒤
tail이면 tail 앞의 노드를 소멸 시키고 tail을 소멸 시키기.
참고로 구현이 간단한건 전자이지만 속도가 빠른것은 후자입니다...
자... 지금까지 더미가 있는 연결리스트에 대한 썰을 풀어봤습니다.
더미노드를 생성함으로써 편리한 부분이 분명 있습니다.
코드를 구현하는 방식이 똑같아 지기 때문이죠...
뭔 말씀이신지 모르신다면,
다음 시간에 보여드리도록 하겠습니다...
이상 삽잡이였습니다!
'삽질의 현장 > - 자료구조와 알고리즘' 카테고리의 다른 글
| #008_자료구조와 알고리즘_너와 나의 연결고리! 연결 리스트 예제 (0) | 2015.08.06 |
|---|---|
| #007_자료구조와 알고리즘_너와 나의 연결고리! 연결 리스트 (더미 노드X) (0) | 2015.08.06 |
| #005_자료구조와 알고리즘_들어온 순서대로! 큐(Queue) (0) | 2015.08.04 |
| #004_자료구조와 알고리즘_Stack과 동적 프로그래밍 (0) | 2015.08.04 |
| #003_자료구조와 알고리즘_누구보다 빠르게 Quick 정렬 (0) | 2015.08.03 |